Major performance enhancements for faster Assemblies
We are very pleased to announce that we have made some considerable performance upgrades over the past few weeks, which will make the average Assembly run faster by about 20-40%.
"Benchmark"
We ran a few tests for uploads of 1 image, 5 images, 10 images and 20 images on our /image/resize demo page. It's basic, but it already shows how much we have improved. Here is a gist with the results. All the numbers there include uploading and encoding time.
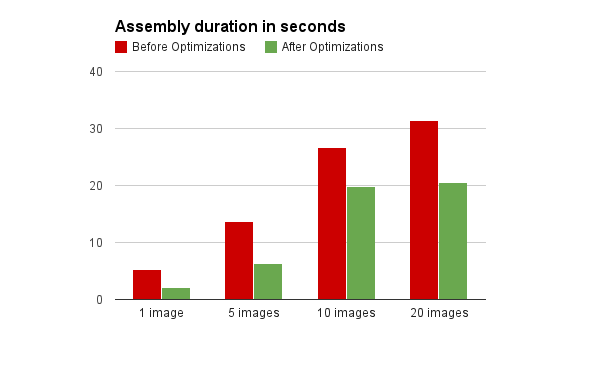
You can see that we had a 54% improvement for 5 images, 25% for 10 images and 34% for 20 images. For 1 image, we even saw a 60% increase in speed. The performance improvement gets worse the more files you upload, because while some files are still uploading, the others are already converted. That means there is less time loss, even with the unimproved version. The fewer files there are in the Assembly, the more apparent the performance improvement becomes.
That also means that for your average Assembly with only one or a few files, you will see a tremendous speed increase.
How did we do this?
For the interested reader, we would like to explain how we did this. 😄
We made a few big upgrades to our system in order to optimize things. While we pride ourselves that all of our encoding and file manipulation already runs in parallel where possible, there was room for such an improvement in a different area.
When you upload files to our service, we first need to extract metadata from them in order to a) return that to you later on, b) to have robots determine which files they can handle and c) to let the /file/filter Robot work its magic.
Also, we need to store all uploaded files and encoding results in our temporary Amazon S3 buckets for machine-to-machine communication. If an encoding machine requires a file, it should be downloaded from Amazon S3 and not from a different encoding machine, otherwise that could easily exceed the machines' I/O limits and cause problems.
We have two types of machines (actually more than that, but that's irrelevant to the optimization)
in production: uploaders and encoders. Uploaders are behind our load balancer, they handle your
incoming assemblies and push jobs into queues. Encoders (encoding machines) take these jobs and
encode them, before reporting their results back. Once all results are accumulated, the uploader
machine that handles your Assembly reports back to the connected client or it sends a
Notification if you use a notify_url.
Optimization 1
We moved metadata extraction for uploaded files from uploader machines to encoder machines. That removes a great deal of load from uploader machines and makes them more responsive and reliable, which is a very nice added benefit of all of this. Since our fleet consists of mostly encoder machines, we now put a lot more computational power behind the metadata extraction task. This causes it to be carried out much faster.
The downside of this is that encoders now first need to download the uploaded files from uploader machines, which meant that we had to build yet another queue system for this (to make sure I/O is not exceeded). There is still more room for improvement, but we will discuss that in a separate announcement.
Optimization 2
We now also let encoder machines store uploaded files on S3, as opposed to doing this on the uploader machines. Also, instead of doing both tasks (S3 storing and metadata extraction) in succession, we made changes so that we can now do them in parallel. These changes were also applied to encoding result files.
Optimization 3
Recently, we changed our underlying S3 software from Tim Kay's AWS tool
to the official AWS Command Line Interface. Tim Kay has done a
wonderful job of maintaining a performant aws utility, but Amazon frequently launches features and
new data-centers and if we want to stay current, we can't expect Tim Kay to spend every free hour on
a tool that he made available for free. As it seemed Transloadit had grown more dependent on this
utility than its author, we decided it would be safer and fair to switch to Amazon's official CLI.
The official AWS CLI, however, demands that you add the right --region parameter to your calls to
it, otherwise it will report an error. S3 Buckets are region dependent.
Our customers often don't define the region parameter when exporting to their buckets and there is
also no way to figure it out without doing time consuming GetBucketLocation and retry requests
first.
Often times though, customers will add a region string to their region-specific bucket name. This also holds true for Transloadit's regional temporary buckets, which are used for inter-machine communication and affect every assembly.
We decided to apply the simple hack of first scanning the bucket name for valid regions and if that exists, using it as the default region for our first attempt.
This is of course not airtight, but we are in the sphere of performance optimization where hacks are
allowed. In any case, our working algorithm for switching regions is still in place as well, should
anyone have US buckets with eu-west-1 in their names.
Just by doing this, we could get the time it takes to complete an S3 operation down from 2.5s to 0.6s, shaving off valuable time at every step.
You can see how this mostly benefits non-US assemblies, which are low on file-size and heavy on step count. If you are a US-based customer that also serves users in Europe, those are also non-US assemblies and this performance boost therefore applies to you as well.
Outlook
We are constantly striving to offer a better service to you and we will continue to come up with upgrades that improve system performance even further. Stay tuned!
P.S. We would like to applaud Tim Kay for his work. It's amazing that the tool he published worked so well, 5 years ahead of the AWS CLI. If our Perl-fu was any better, we would have helped with the maintenance efforts and probably still use it.