Build a Reddit video subtitling bot with Transloadit

It has been a while since we've made a Let's Build, so welcome back to the series.
In this blog, we'll go over how to set up a Reddit bot to automatically subtitle a video and place a comment containing a link underneath it, with Transloadit powering the back-end. We'll be using the Python SDK to link everything together.
We won't be covering setting up a server to host the Reddit bot as that's a bit outside the scope of this post, although the key functionality of the bot will be covered.

Creating the Reddit account
Firstly, create a new Reddit account with the name of your bot, then navigate to https://www.reddit.com/prefs/apps/.
Click Create App, then select script.
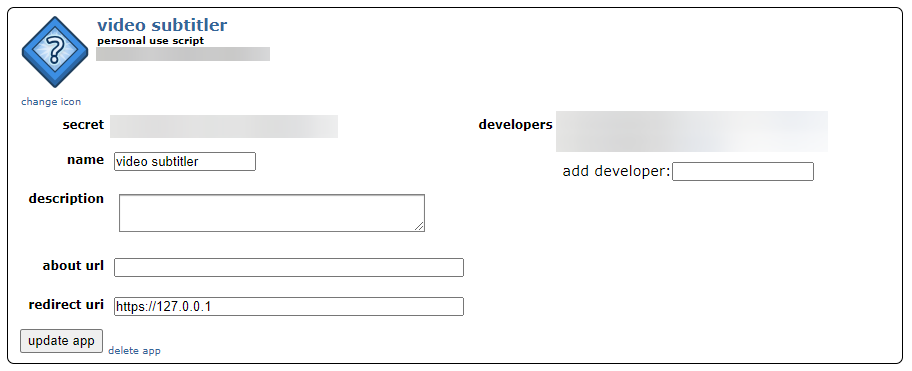
Now, you should be presented with this screen. Make note of the secret and token shown, as we'll need to use them later.
Setting up the Python project
Open up a fresh Python project and install the following packages.
pip install praw
pip install pytransloadit
Now we need to configure our praw.ini file so it's ready to send requests. Navigate to
Lib/Site-Packages/praw/praw.ini, and add the following to the bottom of the file:
[bot1]
client_id=******
client_secret=******
password=[YOUR_REDDIT_PASSWORD]
username=[YOUR_REDDIT_USERNAME]
user_agent=Video Subtitler Bot 0.1
Preparing our Template
Here is the heart and soul of our program. It's long, but we'll go through it step-by-step and break it down.
{
"steps": {
"audio": {
"use": ":original",
"robot": "/file/filter",
"result": true,
"accepts": [["${file.name}", "regex", "audio"]]
},
"video": {
"use": ":original",
"robot": "/file/filter",
"result": true,
"accepts": [["${file.name}", "regex", "video"]]
},
"extract_audio": {
"use": "audio",
"robot": "/video/encode",
"result": true,
"preset": "mp3",
"ffmpeg_stack": "{{stacks.ffmpeg.recommended_version}}",
"rotate": false,
"ffmpeg": {
"vn": true,
"codec:v": "none",
"map": ["0", "-0:d?", "-0:s?", "-0:v?"]
}
},
"merge_audio_and_video": {
"robot": "/video/merge",
"preset": "ipad-high",
"use": {
"steps": [
{
"name": "video",
"as": "video"
},
{
"name": "extract_audio",
"as": "audio"
}
],
"bundle_steps": true
},
"ffmpeg_stack": "{{stacks.ffmpeg.recommended_version}}"
},
"transcribe": {
"use": "audio",
"robot": "/speech/transcribe",
"provider": "gcp",
"format": "srt",
"result": true
},
"subtitle": {
"use": {
"bundle_steps": true,
"steps": [
{
"name": "merge_audio_and_video",
"as": "video"
},
{
"name": "transcribe",
"as": "subtitles"
}
]
},
"robot": "/video/subtitle",
"ffmpeg_stack": "{{stacks.ffmpeg.recommended_version}}",
"preset": "ipad-high",
"result": true
},
"exported": {
"robot": "/s3/store",
"use": "subtitle",
"result": true,
"credentials": "s3defaultBucket"
}
}
}
The first two Steps, video and audio, sort the videos that we will be sending to the
Template into the audio and visual streams. You might be wondering why we don't use the
/http/import Robot here, instead of having to upload
our files. Sadly, it's because Reddit doesn't allow the Robot to download directly from
the CDN, so we have to use this small work-around.
Since audio consists of a video without a video stream, we need to use the
/video/encode Robot in extract_audio to create an
MP3 file by discarding the empty video stream.
We then recombine the audio stream and the original (silent) video in merge_audio_and_video to
form a single video with audio, which we can then pass to transcribe.
By leveraging the Cloud AI features of the
/speech/transcribe Robot, we can create an srt
file, which we'll combine with the video in the subtitle Step. The
/video/subtitle Robot will overlay the subtitles on
the video to produce our final product.
Finally, we can export this to our Amazon S3 bucket, to which we'll post a link in a response comment under the original Reddit post. If you want to learn how to set up an S3 bucket, check out this FAQ page.
Programming our backend
Setup
At the top of your Python file, include the following:
import praw
import re
import os
from transloadit import client
import urllib.request
tl = client.Transloadit('AUTH_KEY', 'AUTH_SECRET')
# Create the Reddit instance
reddit = praw.Reddit('bot1')
trigger_word = 'u/[REDDIT_BOT_USERNAME]'
subreddit = reddit.subreddit('videosubtitlertest')
This contains all of our imports and sets up our Transloadit Client instance and praw instance, the username of our Reddit bot and the name of the subreddit.
Uploading to Transloadit
Next, we're going to create a few functions in order to handle uploading our files to Transloadit.
First of all, we need a small utility function that will download the videos from our URL.
def download_videos(url):
urllib.request.urlretrieve(url, 'video.mp4')
urllib.request.urlretrieve(get_audio_url(url), 'audio.mp4')
You might notice that we're using another function here called get_audio_url. We need this because
Reddit stores the audio and video streams separately, so we have to alter the URL we receive from
Reddit a little bit to retrieve the URL stream.
Luckily, it just takes a quick regex substitution in order to achieve this.
def get_audio_url(url):
audio_url = re.sub(r"(_)[0-9]*", "_audio", url)
return audio_url
Finally, we need the actual function to take the two files that we've just downloaded, and upload them to Transloadit.
def upload_to_transloadit():
assembly = tl.new_assembly({'template_id': 'TEMPLATE_ID'})
assembly.add_file(open('video.mp4', 'rb'))
assembly.add_file(open('audio.mp4', 'rb'))
assembly_response = assembly.create(retries=5, wait=True)
return assembly_response.data['results']['subtitle'][0]['ssl_url']
Finding posts to reply to
Before we can look for posts to reply to, we'll first create a list of post IDs that we've already processed and replied to.
if not os.path.isfile("posts_replied_to.txt"):
posts_replied_to = []
else:
# Read the file into a list and remove any empty values
with open("posts_replied_to.txt", "r") as f:
posts_replied_to = f.read()
posts_replied_to = posts_replied_to.split("\n")
posts_replied_to = list(filter(None, posts_replied_to))
Now we can start our search. For the purposes of testing, I created a subreddit (r/videosubtitlertest) in order to not clog other subreddits as that is generally frowned upon in the Reddit community.
Praw offers us a stream of all submissions to our subreddit, which we can continuously check for new posts that are videos, and that we haven't yet replied to.
Next, we'll go through the comments of this candidate post, and check for a comment that mentions our trigger word – in my case u/video-subtitler-bot. If we find such a comment, then we'll download the submission's video and audio, upload them to Transloadit and return a link to the subtitled video – hosted on our S3 bucket. We'll then add this post to our list of processed posts.
for submission in subreddit.stream.submissions():
# If the post is a video and we haven't replied to it before
if submission.data.domain == 'v.redd.it' and submission.outputPath not in posts_replied_to:
for comment in submission.data.comments:
# If the user's comment contains the bot's name
if trigger_word in comment.data.body:
print("Bot replying to : ", comment.data.body)
download_videos(submission.media['reddit_video']['fallback_url'])
result_url = upload_to_transloadit()
print(result_url)
# Reply to the comment with a link to the video
comment.reply(f"Hi there! Here's the [subtitled video]({result_url}), "
f"processed by [Transloadit](https://transloadit.com/)")
# Store the current id in our list
posts_replied_to.append(submission.id)
Finally, we can save this updated list of posts as a text file.
with open("posts_replied_to.txt", "w") as f:
for post_id in posts_replied_to:
f.write(post_id + "\n")
Limitations
As you may have already noticed, the main issue with our current bot is that you have to leave the script running from your own machine. If you're looking for a way to expand the bot, I'd suggest looking into setting up a Cron Job to automatically run the bot every few minutes from a Linux server. Or, if you'd prefer, simply leave it running on an old laptop, Raspberry Pi, or Heroku account.
Another limitation here is having to download the files locally. Ideally, we would store the files in an Amazon S3 bucket, as this would decrease our processing times substantially. That's a challenge for another day however :)
Final results
As I'm sure you've been eagerly waiting for this part, here's the result produced from our Reddit bot:
The subtitles don't match perfectly in certain parts, but as the technologies available from GCP and AWS improve, so will your results – no upgrades necessary on your end!
Closing up
That's all for this Let's Build! We look forward to seeing how you manage to expand this bot even further, or take it in a direction we didn't think of. Please feel free to get in contact with us on our Twitter or Instagram to show off what you come up with 💪